October 5, 2024
Learn how to automate a scraping task in Retool using Workflows
Web scraping is a common practice for gathering data from public web pages. While it might sound complex, it’s often as simple as reading a webpage's source and using JavaScript selectors to extract the information you need.
In this tutorial, I'll guide you through setting up a Retool Workflow that utilizes Cheerio, a popular jQuery equivalent for server-side environments, to scrape a webpage and extract data.
The first step is to create a new Retool Workflow. Once you’ve done that, the key is adding Cheerio to your workflow. Cheerio lets you load the HTML of a webpage and query it using jQuery-style selectors.
Go to your Retool Workflow editor and add the library:
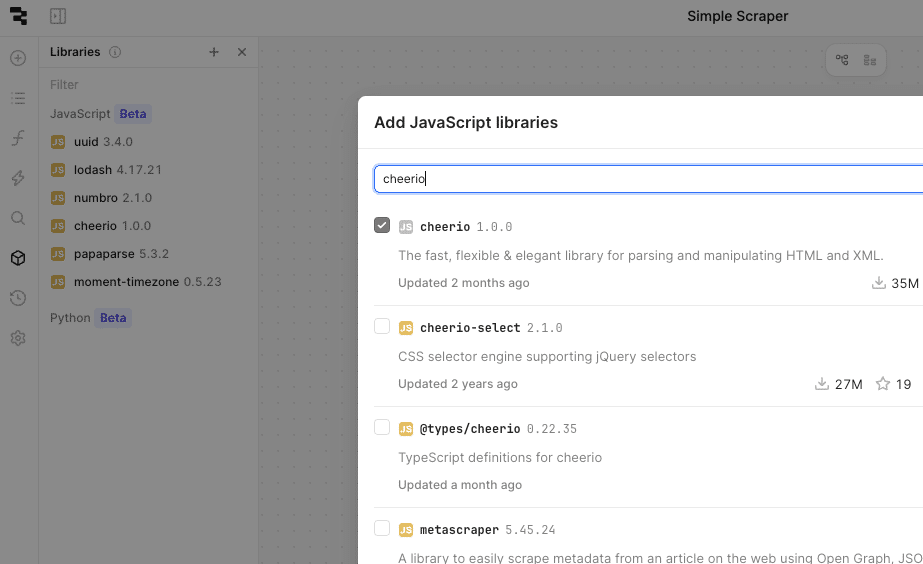
Use the library in a javascript block with something like:
const cheerio = require('cheerio');
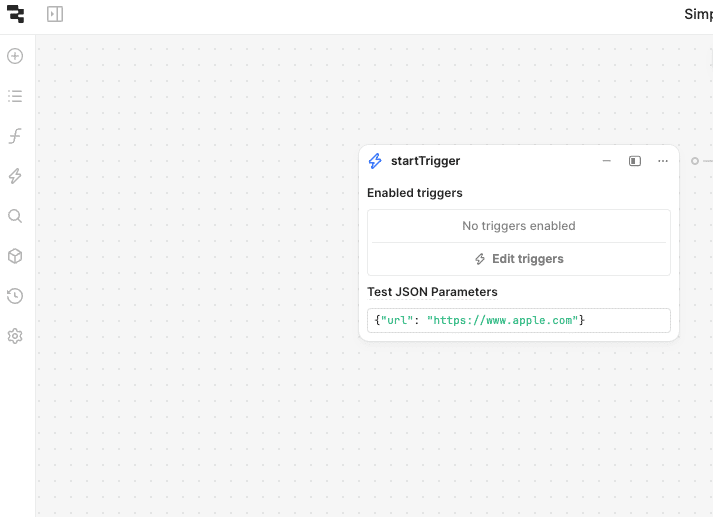
Next, you’ll need to set up your workflow’s start trigger to fetch the HTML source of the target website. Add a sample website URL directly into the start trigger as a parameter.
In the Start trigger block, add a sample URL:
{"url": "https://www.apple.com"}
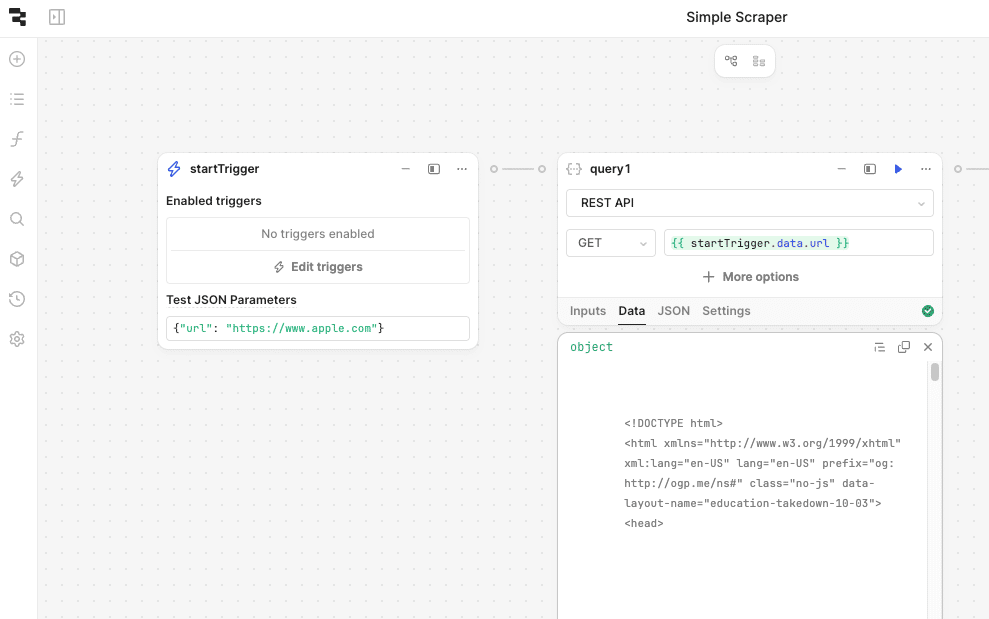
Create a new REST Resource in Retool to make an HTTP GET request to your sample website. When successful, the HTML source will be available in the message field of the response.
Ensure that the response body, which contains the HTML, is stored in query1.data.message.
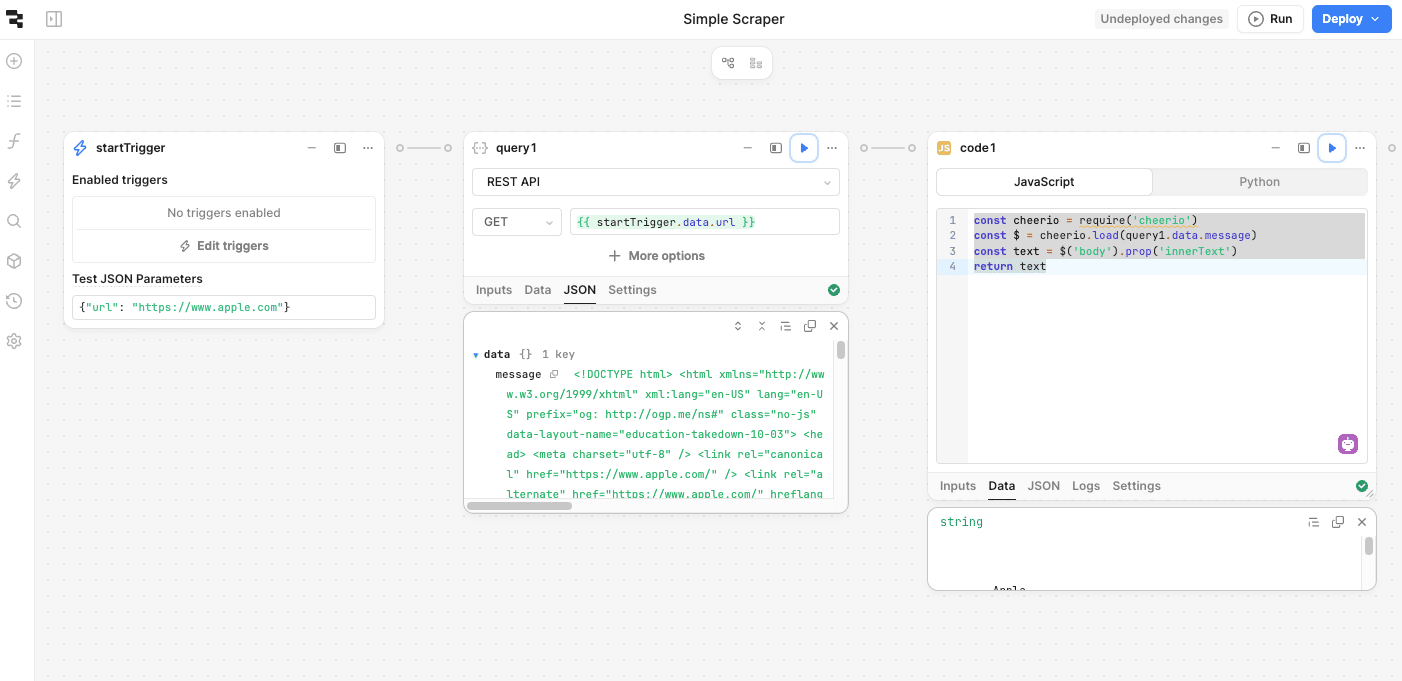
Now, let’s test Cheerio by extracting all the text from the webpage’s <body> tag.
Add a JavaScript block to load the webpage’s HTML into Cheerio and extract the text:
const cheerio = require('cheerio');
const $ = cheerio.load(query1.data.message);
const text = $('body').prop('innerText');
return text;
If Cheerio works as expected, this block should return the inner text of the webpage.
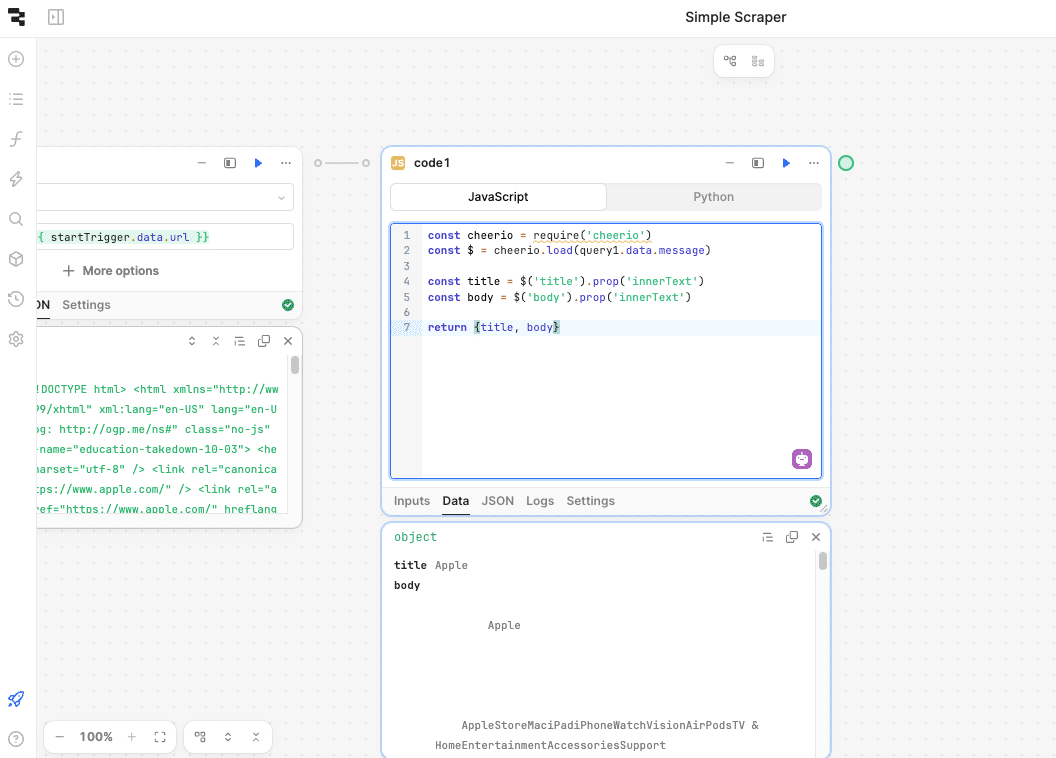
With Cheerio up and running, let’s extract more specific content. For example, we can grab the page title and the body text using jQuery-style selectors.
Update your JavaScript block with the following code:
const cheerio = require('cheerio');
const $ = cheerio.load(query1.data.message);
const title = $('title').prop('innerText');
const body = $('body').prop('innerText');
return { title, body };
This block fetches both the title and body text of the webpage, making it easy to access relevant data.
At this point, you can take your scraping further. You might want to make the scraped data available as a response or store it in a database for later use.
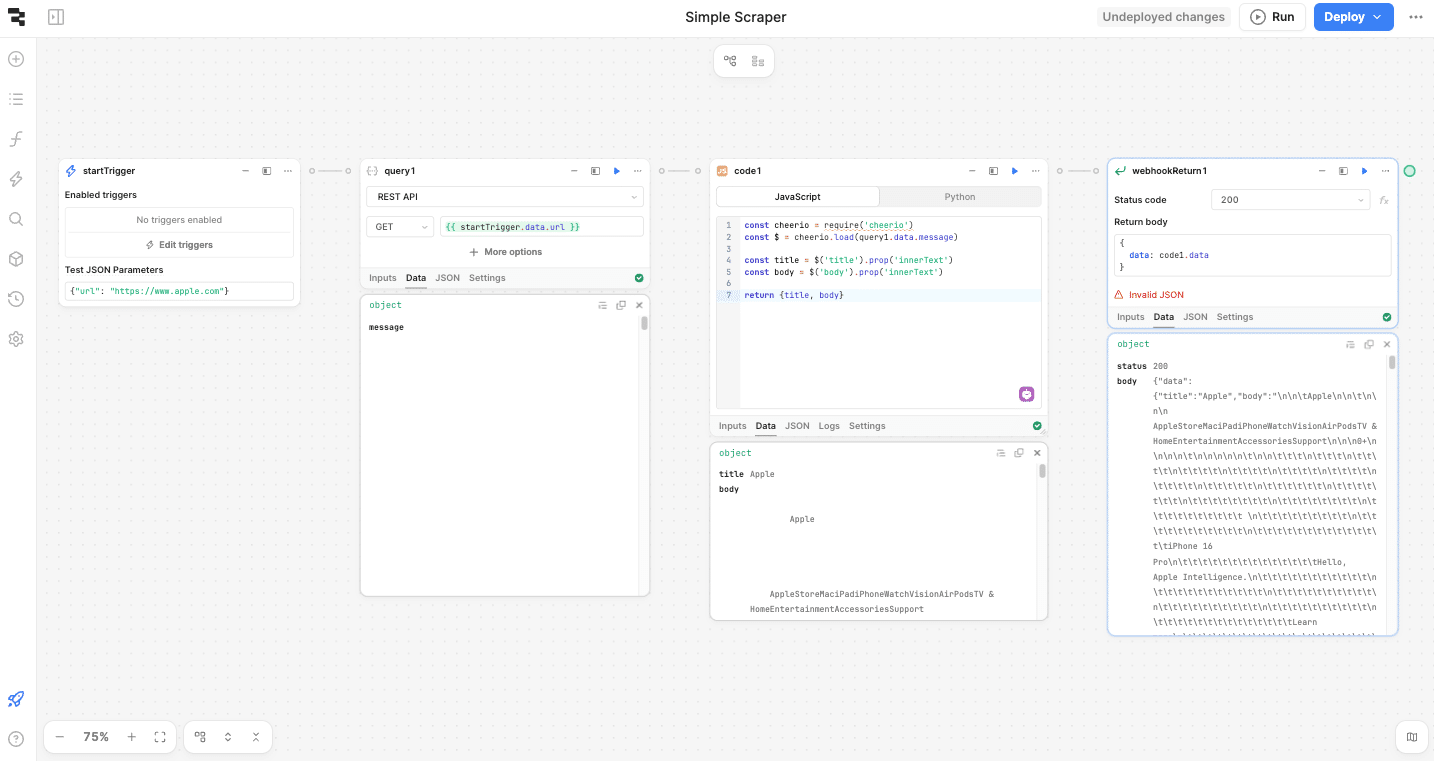
Additionally, you can make your workflow more reusable by passing the target URL as a parameter, allowing you to scrape multiple websites with the same logic.
Web scraping with Retool and Cheerio opens up endless possibilities for collecting data. Whether you're pulling product prices, blog content, or just experimenting, you now have the foundation to start scraping websites efficiently.
We help ambitious companies ride the change
